Evaluation: Audio Features of Music Genres
R Notebook by Miguel Miranda Enriquez
Data source: Kaggle
suppressWarnings(suppressMessages(library(dplyr)))
suppressWarnings(suppressMessages(library(tidyverse)))
df = read.csv("C:\\Users\\mmira\\Downloads\\SpotifyFeatures.csv")colnames(df)## [1] "genre" "artist_name" "track_name" "track_id"
## [5] "popularity" "acousticness" "danceability" "duration_ms"
## [9] "energy" "instrumentalness" "key" "liveness"
## [13] "loudness" "mode" "speechiness" "tempo"
## [17] "time_signature" "valence"Data Transformation
#Merge Children's Music and Children`s Music genre
df$genre[df$genre == "Children's Music"] <- "Children’s Music"#Remove music genres: A Capella, Anime, Children’s Music,
# Classical, Comedy, Movie, Opera, Soundtrack
df <- df[df$genre != "A Capella" & df$genre != "Anime" &
df$genre != "Children’s Music" &
df$genre != "Classical" & df$genre != "Comedy" &
df$genre != "Movie" & df$genre != "Opera" &
df$genre != "Soundtrack",]
head(df)#Remove duplicates and
# create list of multiple genre values in one cell
new_df <- aggregate(df[1], by = df[4],
FUN = unique)
head(new_df)#Sort each list using str_sort function from tidyverse package
new_df$genre <- sapply(new_df$genre, str_sort)#Change list to string
new_df$genre <- sapply(new_df$genre, paste, collapse=",")
head(new_df)#Merge dataframes by performing left inner join using dplyr package
#Drop old genre column
dropped_df = df[,!(names(df)
%in%c("genre"))]
#Merge new genre column
new_df = new_df %>% inner_join(dropped_df,
by="track_id")
#Remove duplicates
new_df = new_df %>% distinct()
head(new_df)new_df# Use mutate funtion to create dummy variables based on if the genre title is contained in the all_genre column
#To avoid using special characters in column names...
# Column name for R&B is RnB
spotify_data <- new_df %>% mutate(
Pop = ifelse(grepl("Pop", genre, fixed = TRUE) == TRUE, 1, 0),
Rap = ifelse(grepl("Rap", genre, fixed = TRUE) == TRUE, 1, 0),
Rock = ifelse(grepl("Rock", genre, fixed = TRUE) == TRUE, 1, 0),
Hip_Hop = ifelse(grepl("Hip-Hop", genre, fixed = TRUE) == TRUE, 1, 0),
Dance = ifelse(grepl("Dance", genre, fixed = TRUE) == TRUE, 1, 0),
Indie = ifelse(grepl("Indie", genre, fixed = TRUE) == TRUE, 1, 0),
RnB = ifelse(grepl("R&B", genre, fixed = TRUE) == TRUE, 1, 0),
Alternative = ifelse(grepl("Alternative", genre, fixed = TRUE) == TRUE, 1, 0),
Folk = ifelse(grepl("Folk", genre, fixed = TRUE) == TRUE, 1, 0),
Soul = ifelse(grepl("Soul", genre, fixed = TRUE) == TRUE, 1, 0),
Country = ifelse(grepl("Country", genre, fixed = TRUE) == TRUE, 1, 0),
Jazz = ifelse(grepl("Jazz", genre, fixed = TRUE) == TRUE, 1, 0),
Electronic = ifelse(grepl("Electronic", genre, fixed = TRUE) == TRUE, 1, 0),
Reggaeton = ifelse(grepl("Reggaeton", genre, fixed = TRUE) == TRUE, 1, 0),
Reggae = ifelse(grepl("Reggae", genre, fixed = TRUE) == TRUE, 1, 0),
World = ifelse(grepl("World", genre, fixed = TRUE) == TRUE, 1, 0),
Blues = ifelse(grepl("Blues", genre, fixed = TRUE) == TRUE, 1, 0),
Ska = ifelse(grepl("Ska", genre, fixed = TRUE) == TRUE, 1, 0),)
spotify_datacolnames(spotify_data)## [1] "track_id" "genre" "artist_name" "track_name"
## [5] "popularity" "acousticness" "danceability" "duration_ms"
## [9] "energy" "instrumentalness" "key" "liveness"
## [13] "loudness" "mode" "speechiness" "tempo"
## [17] "time_signature" "valence" "Pop" "Rap"
## [21] "Rock" "Hip_Hop" "Dance" "Indie"
## [25] "RnB" "Alternative" "Folk" "Soul"
## [29] "Country" "Jazz" "Electronic" "Reggaeton"
## [33] "Reggae" "World" "Blues" "Ska"nrow(spotify_data)## [1] 128794spotify_data_final <- spotify_datacolnames(spotify_data_final)## [1] "track_id" "genre" "artist_name" "track_name"
## [5] "popularity" "acousticness" "danceability" "duration_ms"
## [9] "energy" "instrumentalness" "key" "liveness"
## [13] "loudness" "mode" "speechiness" "tempo"
## [17] "time_signature" "valence" "Pop" "Rap"
## [21] "Rock" "Hip_Hop" "Dance" "Indie"
## [25] "RnB" "Alternative" "Folk" "Soul"
## [29] "Country" "Jazz" "Electronic" "Reggaeton"
## [33] "Reggae" "World" "Blues" "Ska"#Count tracks from each genre combination
genres_df <- group_by(spotify_data_final, genre) %>% summarize(tracks_count = length(genre))
genres_dfCalculate mean, standard deviation, and coefficient of variation for each audio feature corresponding to each music genre combination (489 total)
genre_popularity_summary <- group_by(spotify_data_final, genre) %>%
summarize_at(vars(popularity),
list(pop_mean = mean,
pop_stdev = sd)) %>%
mutate(pop_cv = pop_stdev / pop_mean) %>%
arrange(desc(pop_mean))
genre_popularity_summarygenre_acousticness_summary <- group_by(spotify_data_final, genre) %>%
summarize_at(vars(acousticness),
list(acousticness_mean = mean,
acousticness_stdev = sd)) %>%
mutate(acousticness_cv = acousticness_stdev / acousticness_mean) %>%
arrange(desc(acousticness_mean))
genre_acousticness_summarygenre_danceability_summary <- group_by(spotify_data_final, genre) %>%
summarize_at(vars(danceability),
list(danceability_mean = mean,
danceability_stdev = sd)) %>%
mutate(danceability_cv = danceability_stdev / danceability_mean) %>%
arrange(desc(danceability_mean))
genre_danceability_summarygenre_duration_ms_summary <- group_by(spotify_data_final, genre) %>%
summarize_at(vars(duration_ms),
list(duration_ms_mean = mean,
duration_ms_stdev = sd)) %>%
mutate(duration_ms_cv = duration_ms_stdev / duration_ms_mean) %>%
arrange(desc(duration_ms_mean))
genre_duration_ms_summarygenre_energy_summary <- group_by(spotify_data_final, genre) %>%
summarize_at(vars(energy),
list(energy_mean = mean,
energy_stdev = sd)) %>%
mutate(energy_cv = energy_stdev / energy_mean) %>%
arrange(desc(energy_mean))
genre_energy_summarygenre_liveness_summary <- group_by(spotify_data_final, genre) %>%
summarize_at(vars(liveness),
list(liveness_mean = mean,
liveness_stdev = sd)) %>%
mutate(liveness_cv = liveness_stdev / liveness_mean) %>%
arrange(desc(liveness_mean))
genre_liveness_summarygenre_loudness_summary <- group_by(spotify_data_final, genre) %>%
summarize_at(vars(loudness),
list(loudness_mean = mean,
loudness_stdev = sd)) %>%
mutate(loudness_cv = loudness_stdev / loudness_mean) %>%
arrange(desc(loudness_mean))
genre_loudness_summarygenre_speechiness_summary <- group_by(spotify_data_final, genre) %>%
summarize_at(vars(speechiness),
list(speechiness_mean = mean,
speechiness_stdev = sd)) %>%
mutate(speechiness_cv = speechiness_stdev / speechiness_mean) %>%
arrange(desc(speechiness_mean))
genre_speechiness_summarygenre_tempo_summary <- group_by(spotify_data_final, genre) %>%
summarize_at(vars(tempo),
list(tempo_mean = mean,
tempo_stdev = sd)) %>%
mutate(tempo_cv = tempo_stdev / tempo_mean) %>%
arrange(desc(tempo_mean))
genre_tempo_summarygenre_valence_summary <- group_by(spotify_data_final, genre) %>%
summarize_at(vars(valence),
list(valence_mean = mean,
valence_stdev = sd)) %>%
mutate(valence_cv = valence_stdev / valence_mean) %>%
arrange(desc(valence_mean))
genre_valence_summaryMerge audio features of genre into one dataframe
genres_data_list <- list(genres_df,
genre_popularity_summary,genre_acousticness_summary,
genre_danceability_summary,genre_duration_ms_summary,
genre_energy_summary,genre_liveness_summary,
genre_loudness_summary,genre_speechiness_summary,
genre_tempo_summary,genre_valence_summary)
#Merging multiple dataframes
my_merge <- function(df1, df2){
merge(df1, df2, by = 'genre')
}
genres_df <- Reduce(my_merge, genres_data_list)
genres_dfcolnames(genres_df)## [1] "genre" "tracks_count" "pop_mean"
## [4] "pop_stdev" "pop_cv" "acousticness_mean"
## [7] "acousticness_stdev" "acousticness_cv" "danceability_mean"
## [10] "danceability_stdev" "danceability_cv" "duration_ms_mean"
## [13] "duration_ms_stdev" "duration_ms_cv" "energy_mean"
## [16] "energy_stdev" "energy_cv" "liveness_mean"
## [19] "liveness_stdev" "liveness_cv" "loudness_mean"
## [22] "loudness_stdev" "loudness_cv" "speechiness_mean"
## [25] "speechiness_stdev" "speechiness_cv" "tempo_mean"
## [28] "tempo_stdev" "tempo_cv" "valence_mean"
## [31] "valence_stdev" "valence_cv"#Sort order was lost on merge, resorting
genres_df <- genres_df[order(-genres_df$pop_mean,
genres_df$tracks_count),]
#Remove row index column
row.names(genres_df) <- NULL
genres_dfDetect how many music genre combinations are statistically significant (minimun of 100 tracks)
genres_df[genres_df$tracks_count >= 100,]Visualizations of Music Genres
Irrelevant single genres removed: Movie, A Capella, Anime, Children's Music, Soundtrack,
Comedy, Opera, and Classical.
Total count of single genre tracks after filtering irrelevant genres: 121,411.
Total count of combined genres tracks after filtering irrelevant genres: 73,489
Most combined genres tend to outperform tracks associated with only a single genre. In other words,
tracks associated with more than one music genre tend to be more popular.
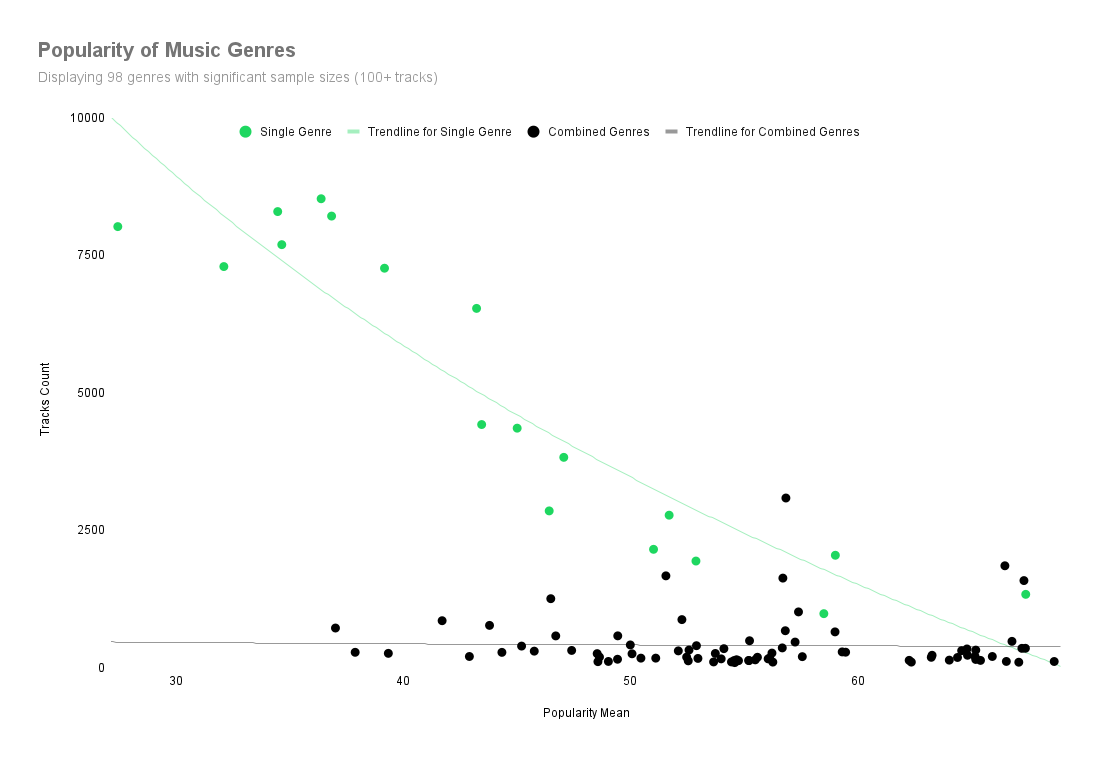
The chart below uses the same dataset as previous graph. A limited amount of single genres are displayed to preserve chart interpretability.

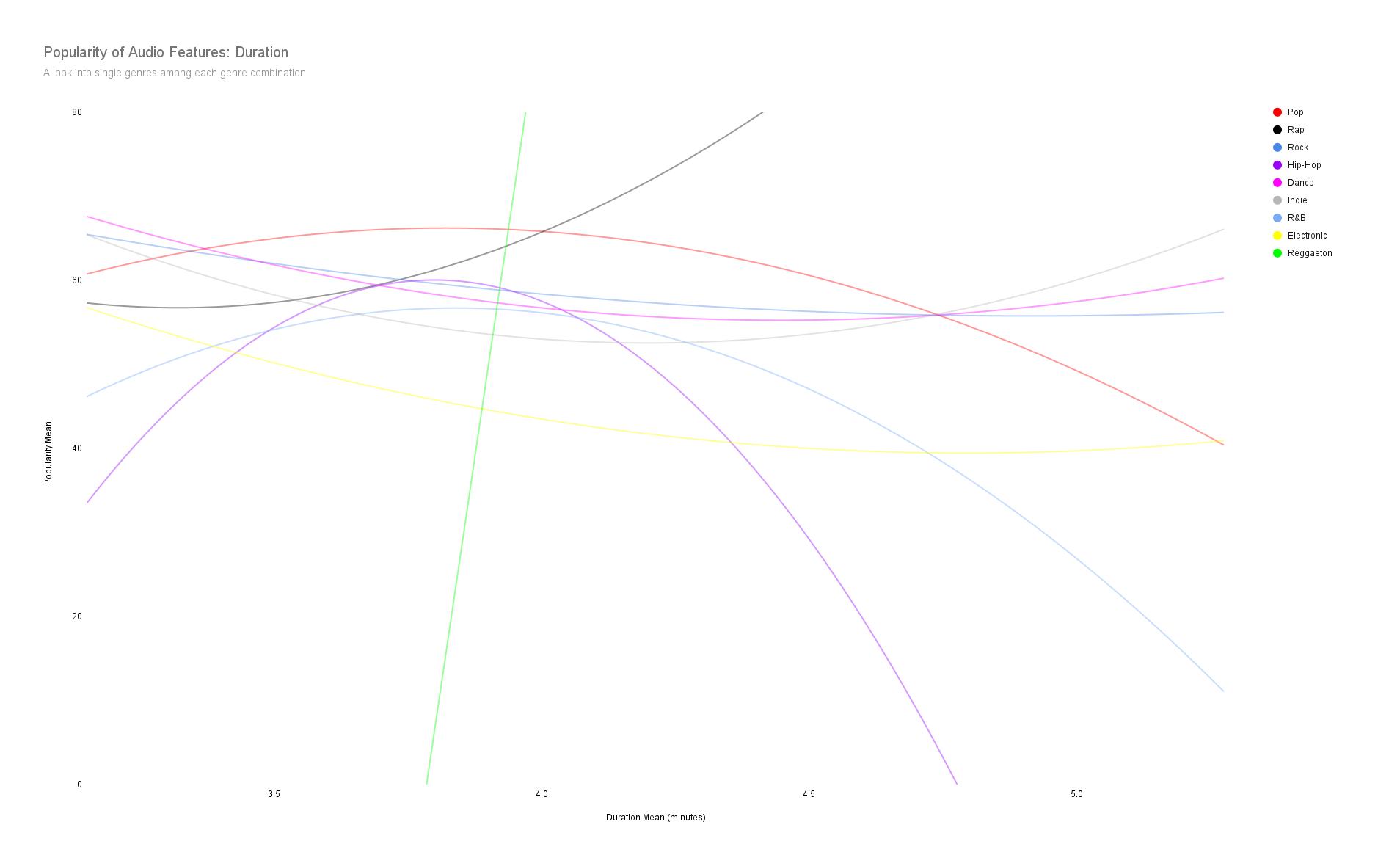
Let's examine how popular some audio features how and which single genres tend to be associated more with a particular audio feature (i.e. energy, danceability, duration, etc..)
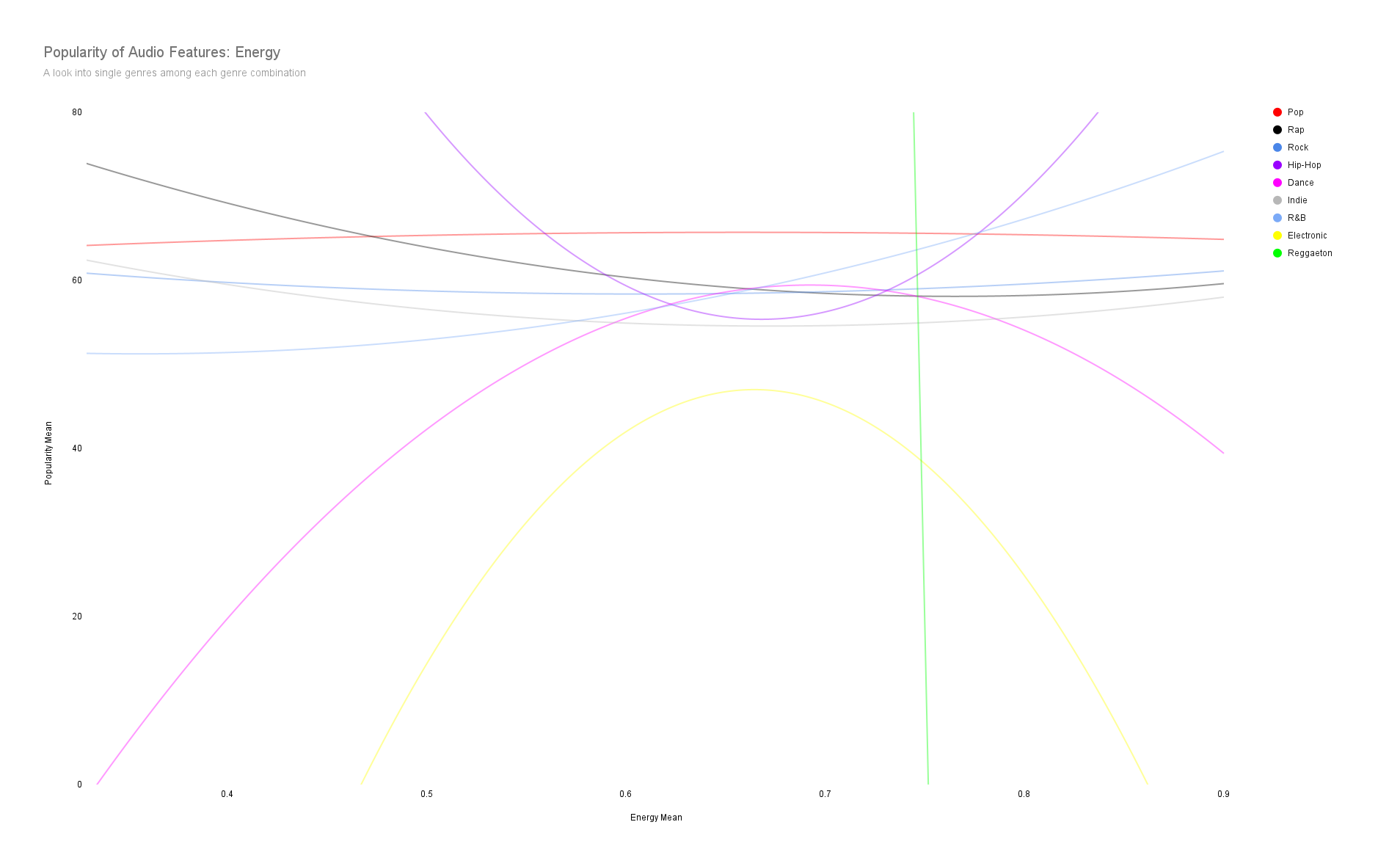
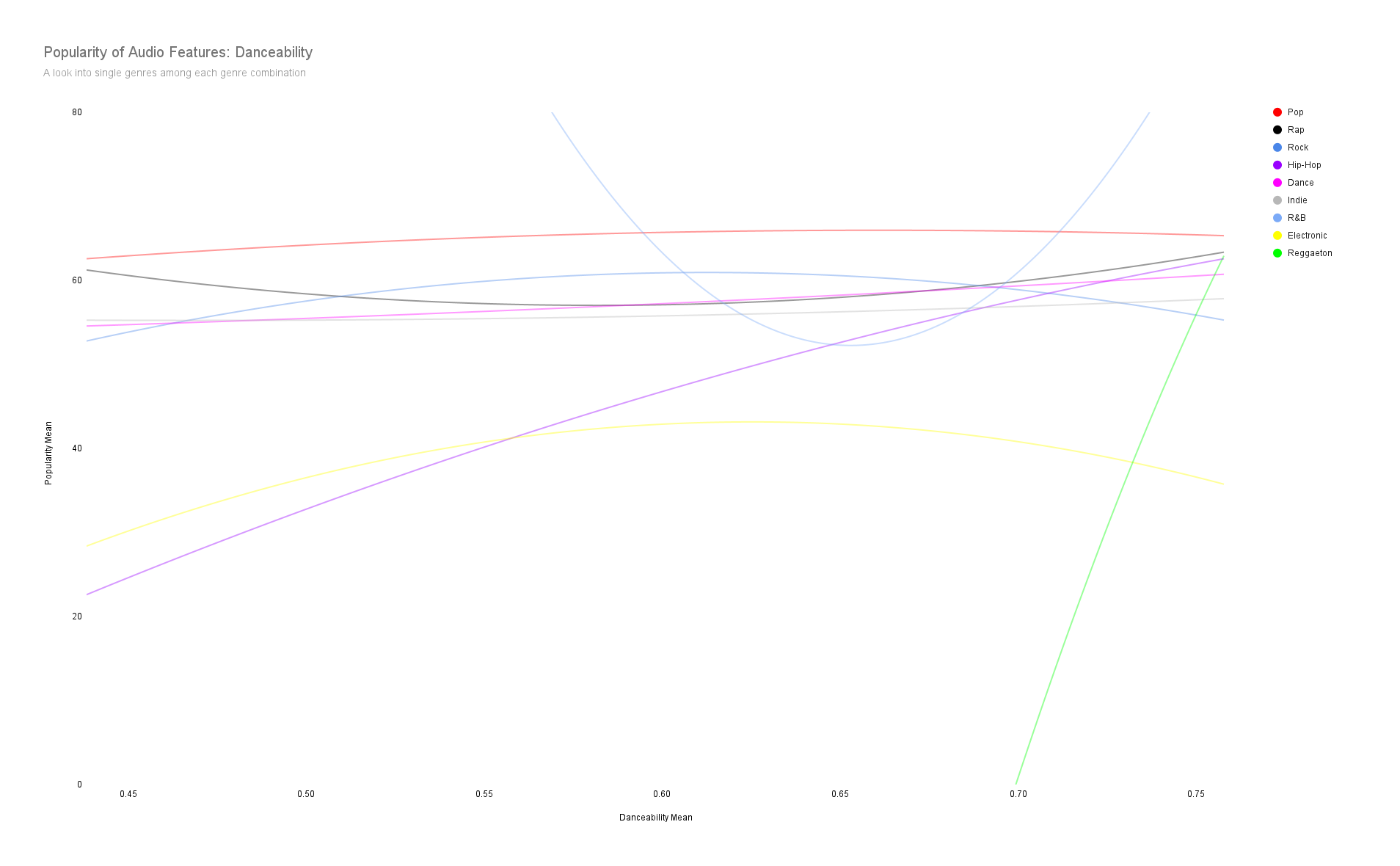
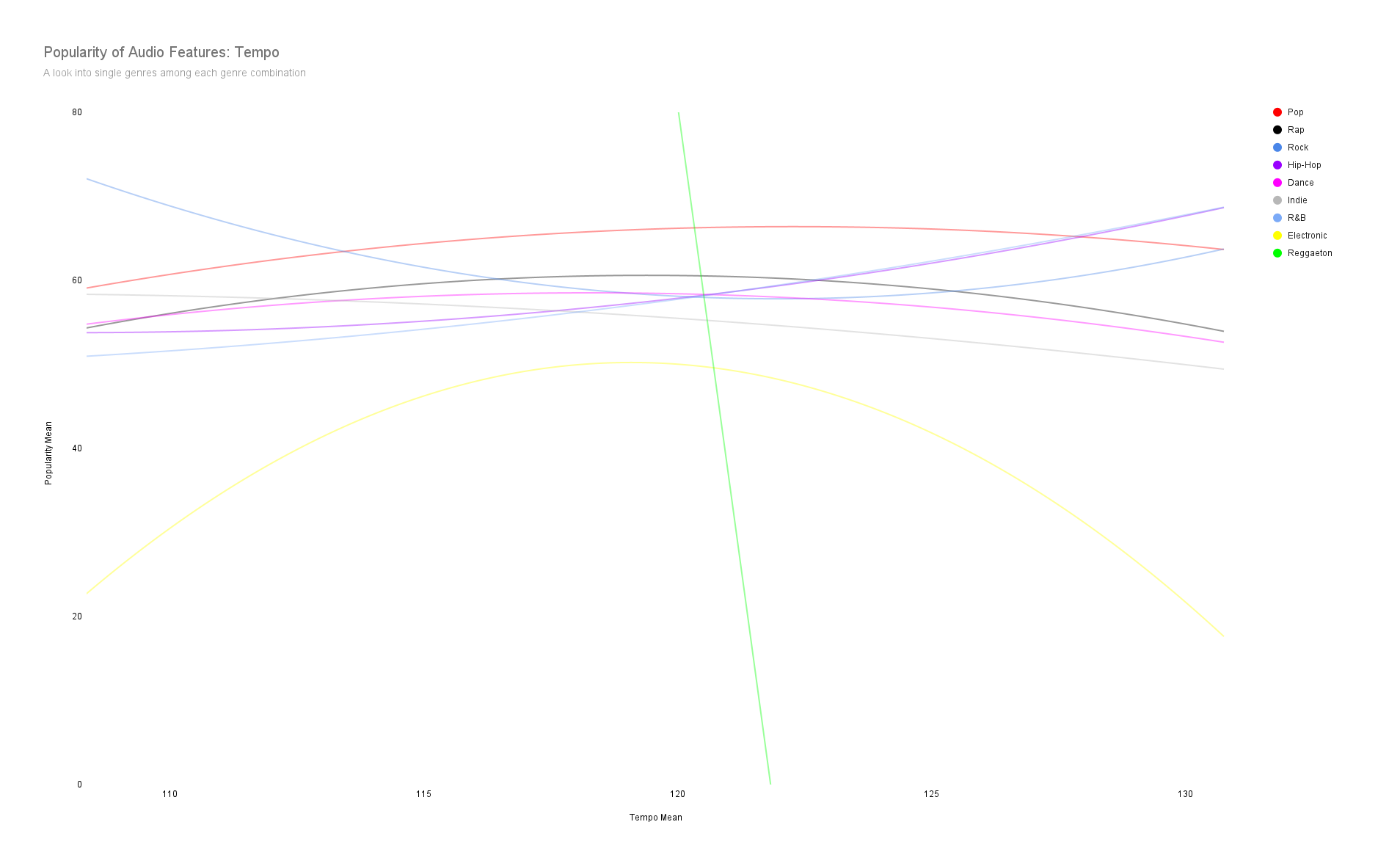
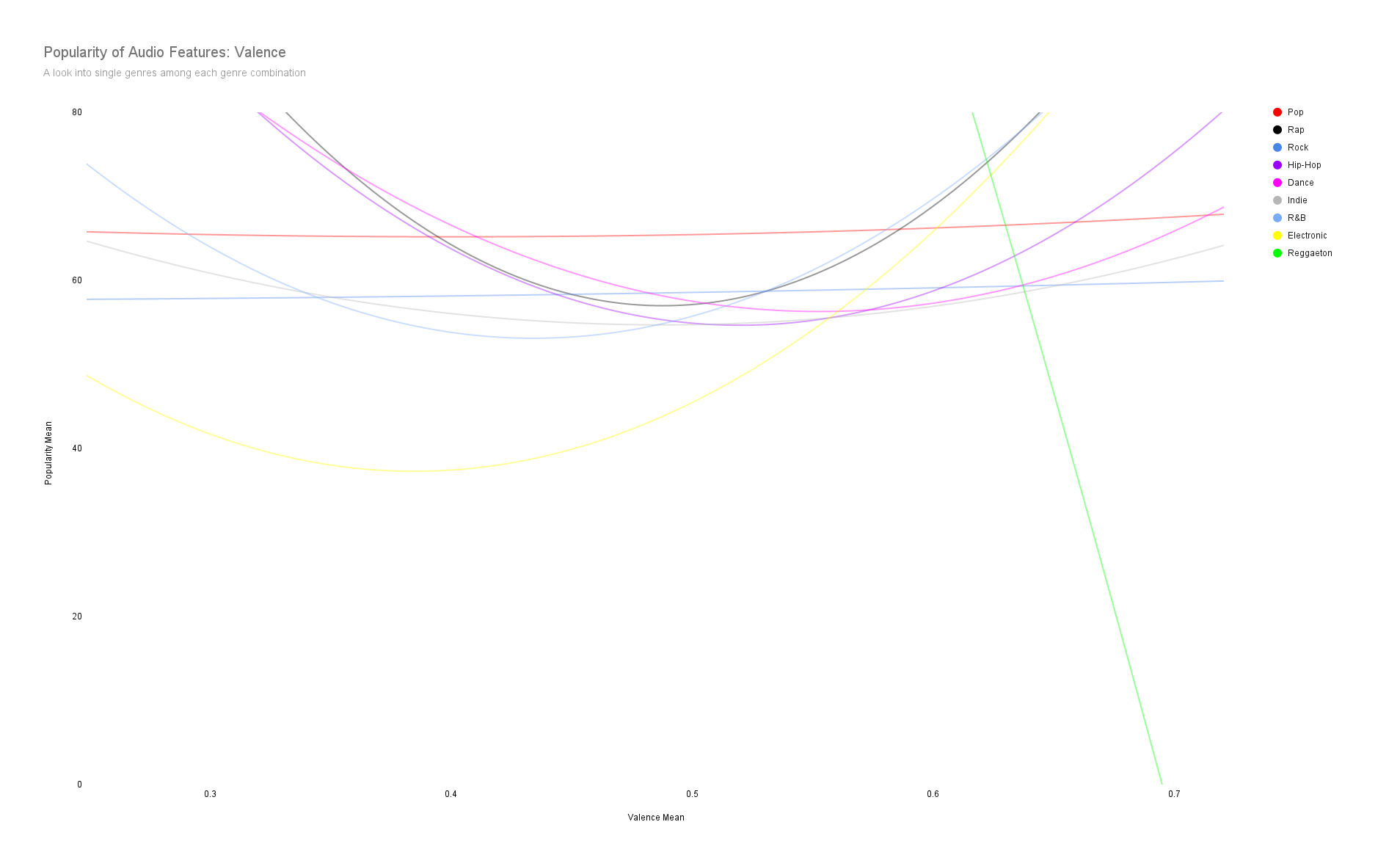
Spotify uses the word “valence” to measure whether a song is likely to make someone feel happy (higher valence) or sad (lower valence).
Conclusion
Songs with elements of Dance, Pop, and Rock genres are the most likely to be profitable.
High correlation between danceability and popularity except
with electronic music.
Beats-Per-Minute (BPM) range of 120-125 is recommended. This range is easy to dance to.
Song duration of ~3.5 minutes is recommended for most genres but for rap music ~4.5 minutes is advised.
Wether a song makes you feel happy or sad doesn't play a significant role except for reggaeton.
Reggaeton songs that are too happy are not as popular.